Song data analysis: Contents
Datasets
To do such study, we have obtained the information from Kaggle. The sets we will work with are the following:
The first dataset has the following format. Artist, song name, web page containing extra information and finally the lyric.

While the second one shows more information than the first dataset, such as the genre of the song or the release year, which we don’t need.
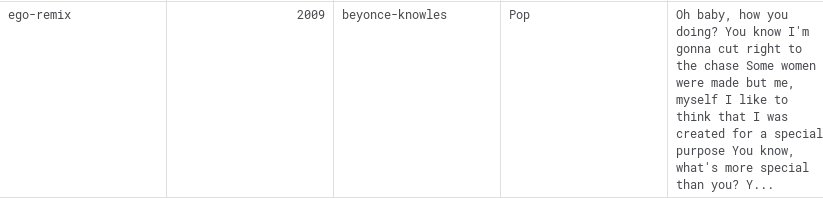
Both datasets needs a preprocesing to remove the extra information before starting to work.
Development Methodology: KDD
The most suitable methodology for this project is KDD, we realized that some iterations would be necessary in order to gather, transform and interpretate the data and, since the raw data was already selected and ready to work with, it had to begin with a selection process. In order to work efficiently, a target data structure was established.
Creating The Target Data Set
The final dataset is composed by a dataframe containing each artist’s most frecuent sentiment and a second dataset containing the relation artist and country. The intersection of both datasets will be the final dataset.
Data Cleaning And Transformation
Both input datasets need to be reestructured, the first one has an extra column and the second dataset has two extra columns belonging to the genre of the song and the release year. Futhermore the order of the columns of both datasets needs to be set, so the second one has to be reordered to merge both dataframes. Lyrics could contain useless words, or signs that may lead to a wrong data interpretation. The text cleaning made at this point to avoid such situation consists on erasing the storpwords such as conjunctions or articles, but also the song’s typical sounds, as it can be seen in the next piece of code.
ASCL[,3] <- removeWords(as.character(ASCL[,3]), words = c(stopwords("english"), "oh", "ah", "eh", "uh", "ma"))
ASCL[,3] <- stripWhitespace(ASCL[,3])
ASCL[,3] <- removePunctuation(ASCL[,3])
Finally, an extract of the final resulting dataframe will be the following, containing in the first column the artists, the song name and finally the lyrics. Some extracts of the final dataset, which contains 419887 entries are the following.

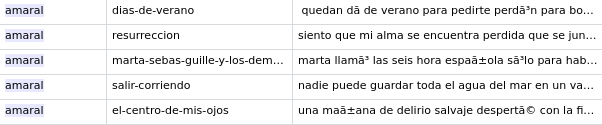
Lyrics contain words that are not useful or that include weird characters, some of them can be seen in the last image. Characters not found in the enlish dictionary doesn’t show, instead a weird character appears. This words are not useful while finding the main feeling and meaning, so we have kept just the most meaningful , removing them and also the so called stopwords. Moreover, we have created several functions relying on the library qdapDictionaries. First, “is.word”, that returns whether the word introduced as a parameter is in the english-spanish language.
is.word <- function(x) x %in% GradyAugmented
Next, making use of the aforementioned function, the “get_existing_words” Main Words And Sentiments function is developed, which name indicates its functionallity.
The second dataframe is built directly from the first one, matching the frequency of each artist based on the amount of songs in the datasets, with its name.
artists <- cbind(as.data.frame(table(ASCL$artist), stringsAsFactors = FALSE), NA)
It is needed to properly write the artist name (i.e. first letter of each word to upper case)
for (i in 1:length(artists$Var1)) {
artists[i, 1] <- paste(unlist(firstup(split_words(artists[i, 1]))), collapse = "_")
}
for a better subsequent cleaning.
Sentiment Extraction
Based on the words extraction from the song lyrics, and using an existing dictionary which returns as key an existing relevant word and as value, the sentiment that is attached to it. It may happen that a single word is attached to several sentiments, as it can be seen in the picture below.
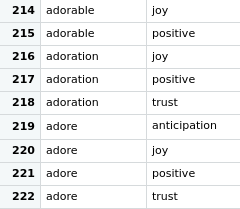
Then, we have traversed in a loop all the different artists and we have concatenated their lyrics, this way, by getting the intersection of each word and the dicctionary above, we get the sentiments that those words evoque. This way, ge can get a list of all the sentiments that an artist share with each word int he lyrics.
After getting this intermediate dataframe, we can extract the frecuency in which each sentiment shows and get the maximum one, to generalice and obtain a general view of the sentiments that each artist try to share based on the R sentiments dicctionary.

Procedence Country
The second dataframe needed to continue with the study is the one that establishes the relation between the artists or bands with its procedence country. The metodology followed to obtain that data is explained in the section Web Mining: Country Extraction. The final dataset is shown in the following picture.
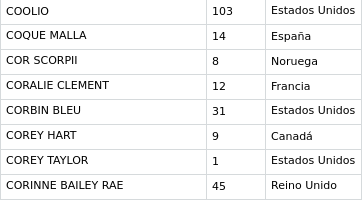
The fist column belongs to the artist, the second to the number of songs and the last column is the procedence country.
Example Of The Final Dataset
After extracting each artist’s primary sentiment and the procedence country of every artist, we can elaborate a table in which the frequency of feelings will be shown.

Data Exploration
Words Frecuency
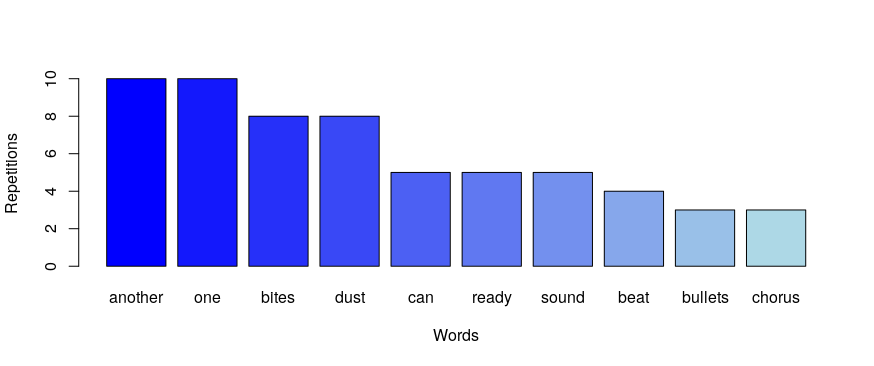
In order to understand the structure of the data in the dataframe obtained, here we show the words with the higher frequency in some of the most relevant Queen songs.
Other examples are shown below.
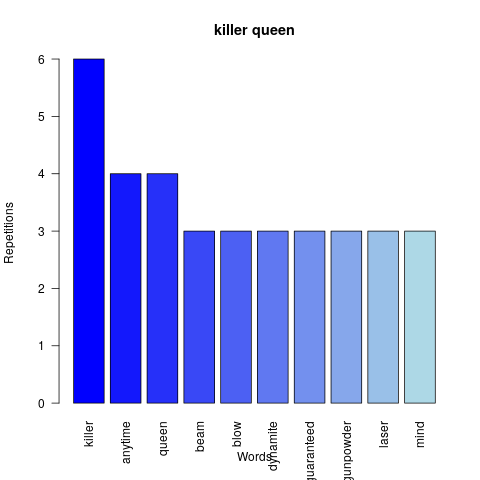
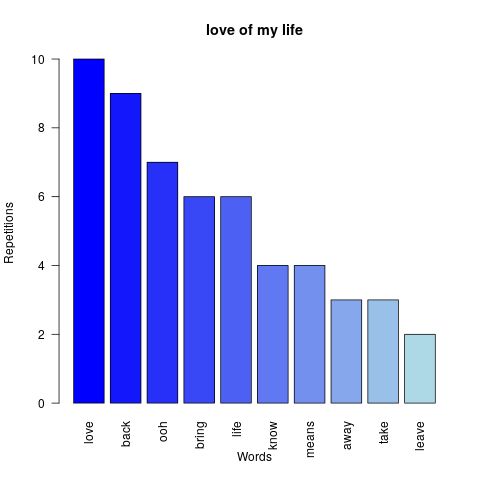
Finally, after visualisation of the possible results of the functions applied to a given band we can build a graph from all the songs. As it is shown, the most common word used by the British band is “love”.
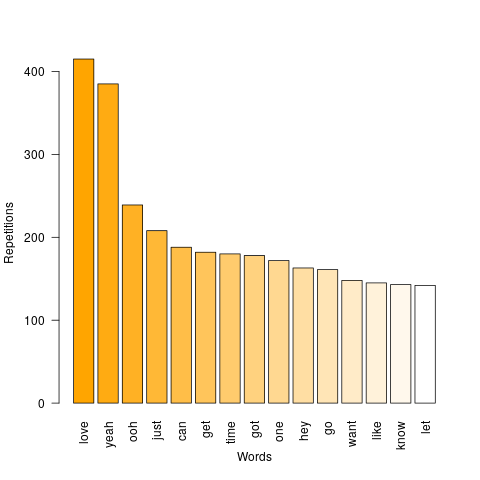
Futhermore, if we study the most used words in a subset containing 400 songs, we obtain the result shown below.

With a higher frequency in the word love.
Sentiments Frecuency
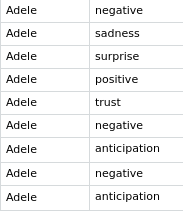
In order to understand the sentiment extraction from the song lyrics, we have explored which are the sentiments more used by the singer Adele in 12 of her songs. Before seeing the results, we established the hypothesis that the main sentiment in her work is sadness or negativity. The results can be seen in the images below.
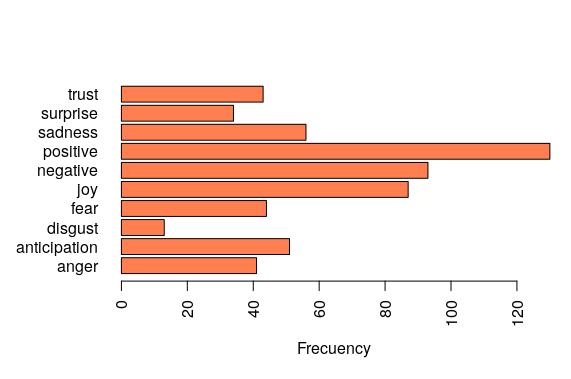
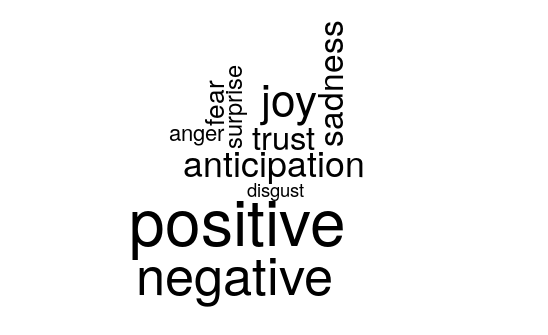
The barplot shows that the most recurrent feeling is positive, which has resulted from the following reasons:
- The 12 songs in the dataset belonging to this Artist is not enough representative.
-
Studying with the word scrapping technique, we can see that this are the most used words:
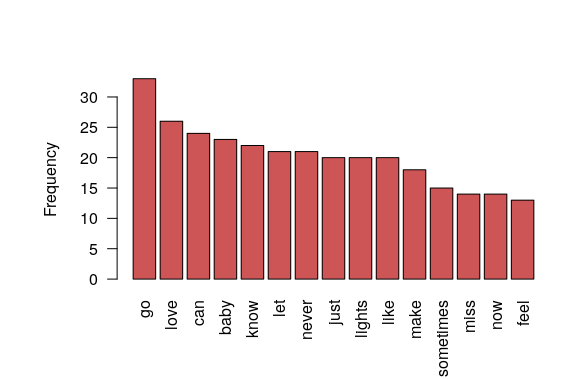
go is not in the sentiments dictionary, but love does, and the sentiments attached to that word are joy and positive, so we can conclude that the usage of this dictionary does not allow us to have into account the context of the word.
As we previously studied Queen’s most used words, we have also extracted which are the most present sentiments.

To continue with a more significant study, we will elaborate on the artist with more frequency in the dataset, which is Dolly Parton, from the USA, with a total of 755 songs.
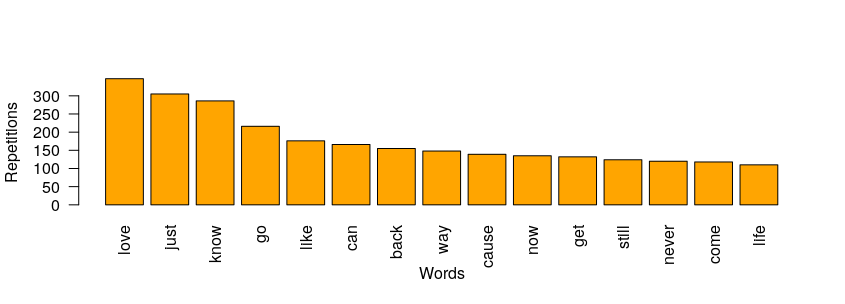
The most used word is, as in the previous examples, love, which will give us a hint to know which is the most relevant sentiment present on this singer’s songs.
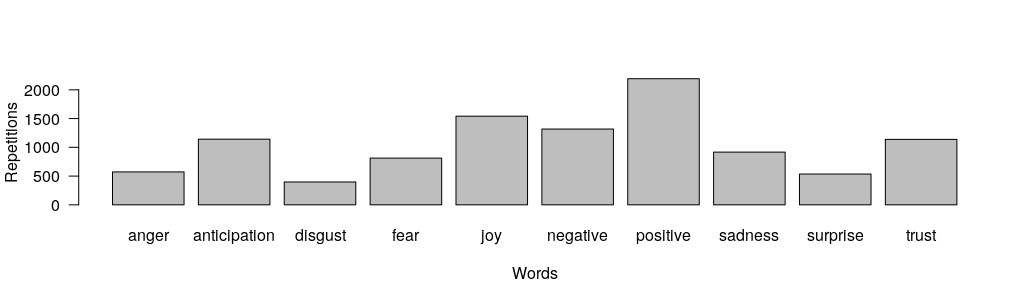
As it can be seen in the previous bar graph, the most frequent sentiment is positive, and it is followed by joy.
Data Mining Algorithm
Main Words And Sentiments
A differentiation among all different words in every song for every artist is key to perform any other action over the dataset or reach a realistic conclusion. Implementing this function returns a list of words that appear in each song and belong to the dictionary. We can use such function to remove choirs and other words that may appear in the lyrics.
get_existing_words <- function(x){
lyric <- list()
all_words <- unlist(stri_extract_all_words(x))
for (w in all_words) {
if (is.word(w)){
lyric <- c(lyric, w)
}
}
return(unlist(lyric))
}
As this funcion has to process every word on every lyric of 419887 songs, it takes too long to execute and we can’t afford that computation capacity. Nevertheless, it can be used to explore the words frecuency, as it is made for a single artist, as it can be seen in section Words Frecuency. We will directly take the important words while extracting the sentiments present on each song.
After having all the different words that an artist has used, we can associate a sentiment to each of them thanks to the following dictionary.
words_sentiments <- get_sentiments(lexicon = "nrc")
The fist step was to organize the big quantity of data present, as we had 419887 entries to process, we grouped them by artist, obtaining a dataframe of lists containing as key the artist and as value the list of lyrics of the existing songs.

Finally, the algorithm traverses every artist’s lyrics and saves in a dataframe the most common sentiment for that artist, by using a function called sentiment_extractor, which returns all the sentiments in a list of words.
function(token_list){
words_sentiments <- get_sentiments(lexicon = "nrc")
sentiments <- list()
for (token in token_list){
if (any(words_sentiments$word == token)){
sentiments <- c(sentiments, words_sentiments[which(words_sentiments$word == token), 2])
}
}
return(sentiments)
}
After obtaining the sentiment list, we elaborate a table, wich automatically assings frecuencies and then create the final dataframe Artist_most_used_sentiment
Artist_sentiments.freq <- table(Artist_sentiments)
Artist_most_used_sentiment <- data.frame(rownames(Artist_sentiments.freq), colnames(Artist_sentiments.freq)[apply(Artist_sentiments.freq, 1, which.max)])
names(Artist_most_used_sentiment) <- c("Artists", "Sentiments")
This lines return the last dataframe shown in Sentiment Extraction.
Web Mining: Country Extraction
In order to establish a relation between the artist’s sentiment and the country’s we need to obtain the precedence country of each artist in the dataset. Using Wikipedia, we can obtain that information, taking into account that each artist’s url can have different formats, we have tried with every possibility, traversing each artist in the dataset.
pwebs <- c(paste("https://es.wikipedia.org/wiki/", artists[i, 1], sep=""),
paste("https://es.wikipedia.org/wiki/", artists[i, 1], "_(banda)", sep=""),
paste("https://es.wikipedia.org/wiki/", artists[i, 1], "_(cantante)", sep=""),
paste("https://en.wikipedia.org/wiki/", artists[i, 1], sep=""),
paste("https://en.wikipedia.org/wiki/", artists[i, 1], "_(singer)", sep=""),
paste("https://en.wikipedia.org/wiki/", artists[i, 1], "_(band)", sep=""))
Those are all the formats that we have found in which an artist or band web page is shown. After that, by using the function exists <- sapply(pwebs, url_exists) we obtain which of the following links exists, and just by taking the first one that exists we can access the table that contains the personal information.
We would finally call these functions to obtain the country from either an english or an spanish source.
country <- extract_country_es(a, existing_countries_es, world.cities)
country <- extract_country_en(a, existing_countries_en, world.cities)
Results
To conclude, we have extracted the most frecuent sentiment for each artist or band in the dataset and we have shown in the following graph which are the feelings more frecuently used.
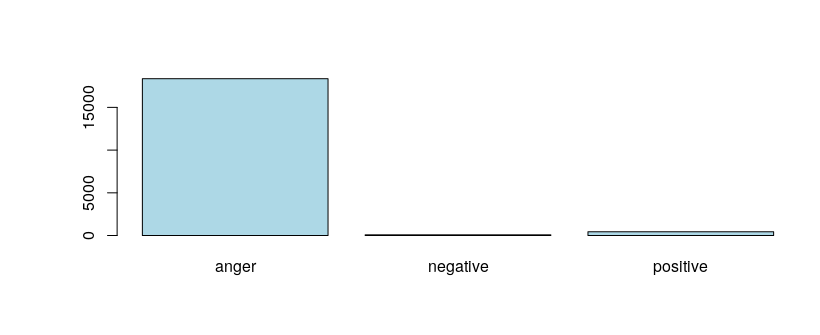
Now we take a closer look to see wheter the individual result matches the overall sentiment. Lets start with some of the countries with more songs in the dataset.
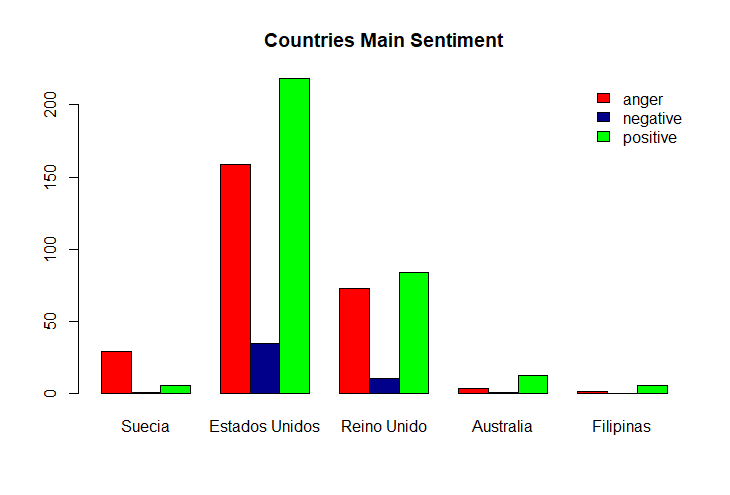
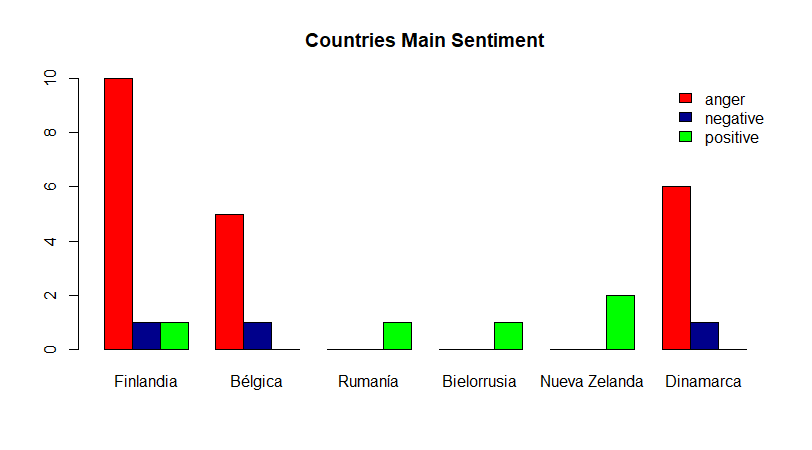
The intuitive conclusion is that the positive feeling may be more relevant due to USA’s frequency but if we look on further countries it is anger the one with the highest value.
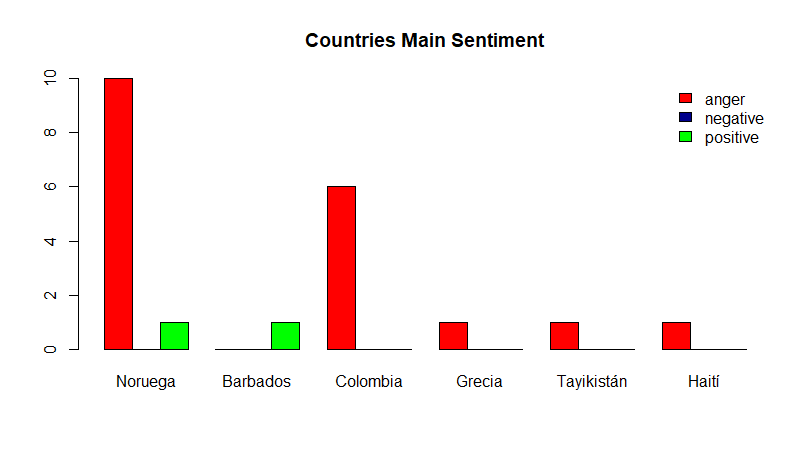
Some of other relevant countries which have the higher frecuency of songs in our datasets are the following. As mentioned, the average sentiment turns into anger the deeper we go into the country list.
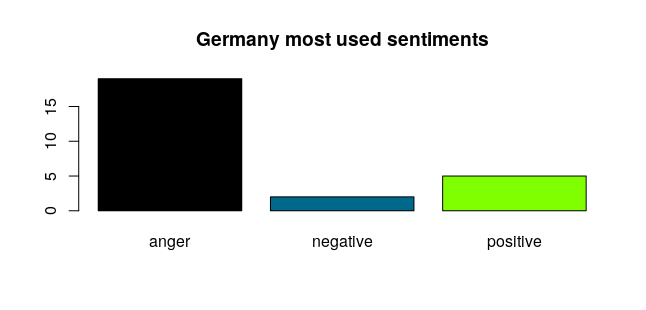
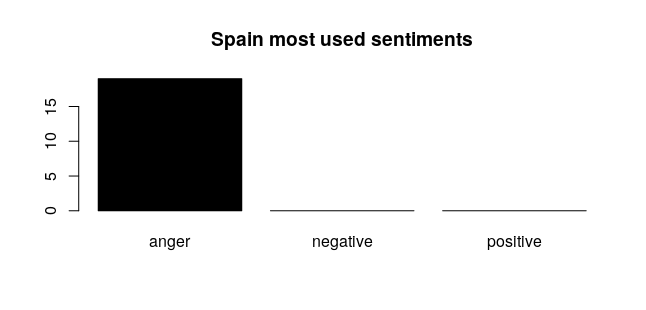
Conclusions And Future Work
In conclusion, we have obtained a close summary of sentiments based on the most used words for each artist which has been grouped by the country of origin. We can now tell what the main theme of the songs in a certain country is. It is yet room for improvement and we are working on finding a relation between the artist-country-sentiment triple, as for a correct traduction and interpretation of foreing lyrics.